
By Alex Woodie

Companies have long dreamed of a single data platform that can handle their real-time and batch data and workloads, without some clunky interface in between. However, unless your name is Uber or Netflix, you probably don’t have the engineering resources to build a modern Lambda architecture yourself.
When he was an engineer at Confluent, Hojjat Jafarpour took a shot at creating a system that moved the ball forward on Apache co-creator Jay Kreps’ dream of a Kappa architecture that solved the Lambda dilemma by reimagining everything as a stream. The result was the 2017 launch of kSQL, which provided a SQL interface atop data flowing through Kafka. By itself, kSQL didn’t create a Kappa architecture, but it filled an important gap.
While kSQL simplified a lot of things, it still had its limitations, said Jafarpour, who was the engineering lead on the kSQL project. For starters, it was tightly coupled to Kafka itself. If you wanted to read and write to other streaming data platforms, such as AWS’s Amazon Kinesis, then you were back to doing software engineering and integrating multiple distributed systems, which is hard.
After moving up into a more customer-facing role at Confluent, Jafarpour gained a new understanding of the types of things that customers and prospects really wanted out of their data infrastructure. When it came to getting value out of real-time processing systems, real-world companies continued to express frustration with the continued expense and complexity that it entailed.
DeltaStream Founder and CEO Hojjat Jafarpour
That’s what motivated Jafarpour to jump ship in 2020 and found his own company, called DeltaStream. Jafarpour wasn’t ready to give up on SQL or Kafka, but instead he wanted to build a better abstraction for a stream processing product that rode atop existing Kafka and Kinesis pipelines out there.
To guide development at DeltaStream, Jafarpour took his inspiration from Snowflake, which managed to provide a very clean interface for its sophisticated cloud data warehouse.
“We want to make it super simple for you to use it, take away all of the complexity of operations and infrastructure, and you just come and use it and get value from your data,” Jafarpour told BigDATAwire at the recent Snowflake conference. “The idea was to build something similar for your streaming data.”
Instead of reinventing the wheel, Jafarpour decided to build DeltaStream atop the best stream processing engine that existed in the market: Apache Flink.
“We get the power of Flink, but we abstract the complexity of that from the user,” Jafarpour said. “So the user doesn’t have to deal with the complexity, but they would be able to get the scalability, elasticity and all of the things that Flink brings.”
Jafarpour observed that one of the most common use cases for Flink deployments is to process fast-moving data to ensure that downstream dashboards, applications, and user-facing analytics are kept up-to-date with the freshest data possible. That often meant taking streaming data and loading data into some type of analytics database, where it can be consumed as a materialized view.
“A lot of use cases people would run Flink with something like Postgres, Clickhouse, or Pinot, and again, you have two different systems to manage,” Jafarpour said. “As I said, we wanted to build a complete data platform for streaming data. We saw that a lot of streaming use cases need that materialized view use case. Why not make it as part of the platform?”
So in addition to Apache Flink, DeltaStream also incorporates an OLAP database as part of the offering. Customers are given the option of using either open source Clickhouse or Postgres to build materialized views to serve downstream real-time analytics use cases.
“The good thing is that we are a cloud service, so under the hood we can bring in these components and put them together without customers having to worry about it,” Jafarpour said.
DeltaStream, which raised $10 million in 2022, has been adopted by organizations that need to ingest large amounts of incoming data, from IoT sources or change data capture (CDC) logs. The company has customers in gaming, security, and financial services, said Jafarpour, who previously was an engineer at Informatica and Quantcast and has a PhD in computer science.
Earlier this month, the Menlo Park, California company rolled out the next iteration of the product: DeltaStream Fusion. The new edition gives customers the ability to land data into Apache Iceberg tables, and then run queries against those Iceberg tables.
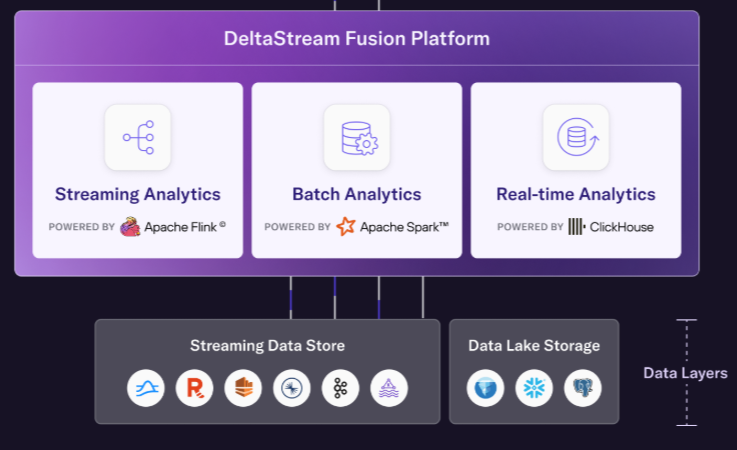
DeltaStream Fusion uses Flink, Spark, and Clickhouse for streaming, batch, and real-time use cases
To power DeltaStream Fusion, Jafarpour surveyed the various open source engines available on the market, and picked the one he thought was best fitted for the job: Apache Spark.
“Spark is the proper tool for batch. Flink is good for streaming, even though both of them want to do the other side,” Jafarpour said. “The good thing is that we abstracted it from the user. If it’s a streaming query, it’s going to compile into a Flink job. If it’s a query for the Iceberg tables, it’s going to use Spark for running that query.”
Ironically, Confluent itself would follow Jafarpour’s lead by adopting Flink. In 2023, it spent reported $100 million to buy Immerok, one of the leading companies behind Apache Flink into its offerings. The company hasn’t completely abandoned kSQL (now called ksqlDB), but it’s clear that Flink is the strategic stream processing engine at Confluent today. Databricks has also moved to support Flink within Delta Lake.
Jafarpour is philosophical about the move beyond kSQL.
“That was one of the first products in that space, and usually when you build a product the first time, you make a lot of decisions that some of them are good, some of them are bad, depending on the situation,” he said. “And as I said, as you build things and as you see how people are using it, you’re going to see the shortcomings and strength of the product. My conclusion was that, okay, it’s time for the next generation of these systems.”
Related Items:
Slicing and Dicing the Real-Time Analytics Database Market
Confluent Expands Apache Flink Capabilities to Simplify AI and Stream Processing
Five Drivers Behind the Rapid Rise of Apache Flink
The post DeltaStream Dreams: Bringing Batch, Streaming, and Real-Time Together appeared first on BigDATAwire.
Read more here:: www.datanami.com/feed/




