
By Alex Woodie

There’s something lurking in your file systems and object stores. It’s called unstructured data, and it’s growing into a massive blob that threatens to eat up storage costs, violate security and privacy regulations, and derail your AI initiatives. Is there any way to conquer it?
Getting a handle on this unstructured data is becoming a C-suite priority, for both offensive (GenAI) and defensive (regulatory) reasons. But the very nature of unstructured data makes it difficult to manage. After all, how do you classify words and pictures? How do you archive petabytes of log files? And perhaps most importantly, how do you enforce access control across thousands of disparate data silos?
The challenge and opportunity of unstructured data management is driving IT vendors to expand their reach into the unstructured realm. One vendor that’s been treading the unstructured waters for some time is Data Dynamics. Piyush Mehta, a self-described “accounting finance guy,” founded the New Jersey software company in 2012 with the goal of addressing some of the data management challenges he saw companies struggling with.
The first thing that Mehta noticed was that everybody seemed to have their own definition of what “data management” meant.
Unstructured data includes text, images, video, audio, IoT, and other types of files
“If you look at it from a CISO perspective, it’s ‘How do I manage my risk as it’s associated to data?’” Mehta says. “If you talk to the CDO, it’s ‘Do I have proper understanding of classification and the journey of how that data is funneled to the right location?’ And then if you look at it from a CIO perspective, it’s lifecycle management: How do I ensure I provide the right storage resources? How do I provide and make sure that I have proper hygiene around when that data gets stored and where and what we find?”
That silo-ization of data management thinking leads to a proliferation of data management tools. It’s not uncommon to see a single enterprise have 15 to 18 different point solutions to address various aspects of the data management challenge, from risk, classification, or lifecycle management, he says.
“And that gets extremely complicated,” he tells BigDATAwire in a recent interview. “You’re scanning the same data multiple times. So that led us to saying, hey, there must be a better way.”
Big Data Wave Crashes
In the old days (i.e. the 2010s), we all thought a petabyte or two of data sitting on a file system or an object store was a big deal. But that data primarily was residing on secondary storage. The real important data, the stuff powering business applications and driving decision-making, was sitting on block storage, on SANs backing the database.
But things have changed, and today, there’s really no difference between the block and the file storage, Mehta says.
“You have high performance applications running with object store on the back end, because it performs better as a single, flat layer to analyze data from,” he says. “You have hierarchical file systems that are extremely fast and performance-ready.”
Today, it’s not uncommon for customers to have several hundred petabytes of unstructured data sitting on file systems and object storage, with hundreds and billions of files or objects. That data is spread across geographic spans and across different storage arrays.
“And then you add cloud,” Mehta says. “So your level of complexity and sprawl is massive and control and context is dependent on where it sits, whose is it, which line of business tie into it.”
Managing that massive web of data and storage is difficult enough. But when you add in the disparate views of the CIOS, CDO, and CIO, it becomes a convoluted mess. Data Dynamics’ pitch is that it can help manage all that unstructured data spread across disparate silos, while delivering different capabilities to different users and different use cases.
For instance, large enterprises are especially concerned right now about the privacy and security implications of mis-managing that data (as they should be). But at the same time, these massive troves of unstructured data are veritable gold mines of data, just waiting to be tapped into with GenAI. Balancing that desire to access the unstructured gold along with the desire to keep the company off the cover of the Wall Street Journal for being the victim of the latest hack, is the real trick.
Unstructured Data Treats
The big challenge associated with unstructured data is that this data is not anything that’s nice and structured, sitting in a databases like SQL Server or Oracle, Mehta says. Much of it’s generated by various applications.
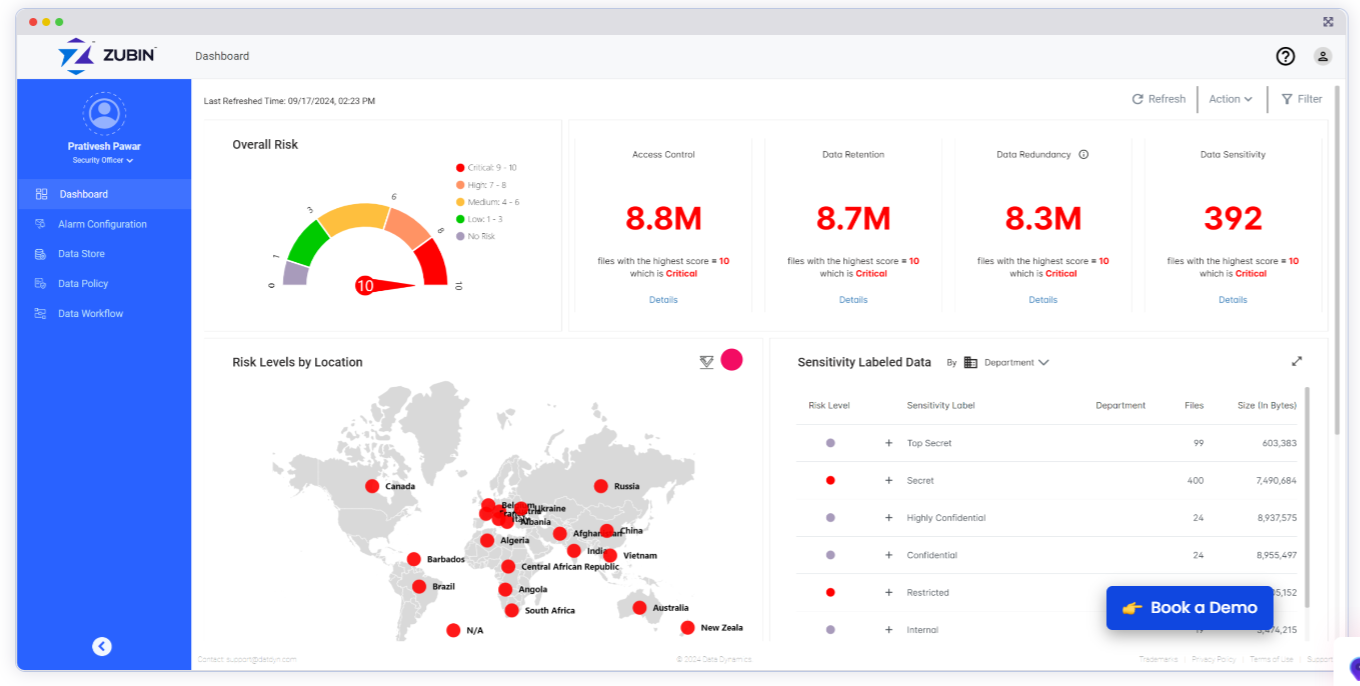
Zubin is Data Dynamics latest product for unstructured data management
“It could be tick files that are generated in the finance world,” he says. “It could be log files that are generated across the board. It could be IoT device information. It could be seismic files in the world of energy. It could be patient records or clinical trial information or PACS (pictures archiving and communication systems) images in the world of healthcare.”
Data Dynamics’ first product, called Storage X, was aimed primarily at migrating this data from one repository to another. When Mehta realized that customers were simply lifting and shifting their data, thereby perpetuating the GIGO problem, he realized that better analysis was needed. That led to the acquisition of a company out of Pune, India that developed a metadata analytics tool, which the company has expanded on.
Metadata-based analytics are needed to derive better intelligence about the data enterprises have stored across file systems and object stores, including NFS/SMB and S3-comptabile object stores, as well as storage offerings from vendors, like Microsoft SharePoint, VAST Data, NetApp, Dell, and Hitachi Vantara.
“Most of our enterprise customers have hundreds of billions of files, so if you say, hey, I need to open each file to look within the content, it’ll be quite some time,” Mehta says. “So we ended up adding a thing called statistical sampling, which said ‘Hey, let’s pick the metadata as a filter and then be smart about what do we find, and what accuracy level does it offer us in terms of the content that we’re looking for within those files.’”![]()
As the company matured, it shifted its focus from storage optimization and data migration to data democratization. Its latest offering, dubbed Zubin, builds upon Data Dynamics’ previous capabilities to give its 300 customers the capability to centrally manage the policies for disparate silos of unstructured data.
Once data is classified at the corporate level in Zubin, which was unveiled last month, it’s up to the individual application or data owners to define what users can access that data, via role-based access control (RBAC). That give customers the capability to centrally define data management across the spectrum of repositories, from on-prem storage to cloud storage, while freeing up managers who are closer to the users to make data access decisions.
The company has a theme, called “Bytes to Rights,” that reflects its ideas about data democratization.
“How do you empower the data?” Mehta says. “For us, that’s a very important thing because we truly believe that every enterprise is the custodian of the data that they hold, whether it’s their people’s data or whether it’s their customers data, in which case, how do we help them become better custodians?”
Related Items:
Nurturing Data Sovereignty in a World Powered by Technology
Data Dynamics Introduces AI-Powered Zubin as a Self-Service Approach to Modern Data Management
Unstructured Data Growth Wearing Holes in IT Budgets
The post Peering Into the Unstructured Data Abyss appeared first on BigDATAwire.
Read more here:: www.datanami.com/feed/




